2015-04-03
PCA、LDA、NMF都可以用来降维。
之前在 使用PCA处理MNIST数据集 介绍过PCA,在 隐语义模型和NMF(非负矩阵分解) 介绍过NMF。
这里的LDA,是指线性判别分析(Linear Discriminant Analysis),是一种有监督的学习方法。这方面的资料可以参考:
PRML(Pattern Recognition and Machine Learning)第四章
本文内容是如何使用scikit-learn中的这3个降维工具处理Iris数据集,并用图的形式比较了降维效果。
导入数据集
>>> from sklearn.datasets import load_iris
>>> import numpy as np
>>> iris = load_iris()
>>> iris.data
array([[ 5.1, 3.5, 1.4, 0.2],
[ 4.9, 3. , 1.4, 0.2],
....
[ 5.9, 3. , 5.1, 1.8]])
>>> iris.target
array([0, 0, 0, 0, 0, 0, ... , 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
>>> iris.data.shape
(150, 4) # 150个样本,每个样本4个特征
>>> iris.target.shape # 每个样本的类别
(150,)
PCA
>>> from sklearn.decomposition import PCA
>>> pca = PCA(n_components=2)
>>> pca_result = pca.fit_transform(iris.data)
LDA
>>> from sklearn.lda import LDA
>>> lda = LDA()
>>> lda = LDA(n_components=2)
>>> lda_result = lda.fit_transform(iris.data, iris.target)
NMF
>>> from sklearn.decomposition import NMF
>>> nmf = NMF(n_components=2)
>>> nmf_result = nmf.fit_transform(iris.data)
画图
>>> import matplotlib.pyplot as plt
# for PCA
>>> plt.subplot(1,3,1)
>>> plt.scatter(pca_result[iris.target==0, 0], pca_result[iris.target==0, 1], color='r')
>>> plt.scatter(pca_result[iris.target==1, 0], pca_result[iris.target==1, 1], color='g')
>>> plt.scatter(pca_result[iris.target==2, 0], pca_result[iris.target==2, 1], color='b')
>>> plt.title('PCA on iris')
# for LDA
>>> plt.subplot(1,3,2)
>>> plt.scatter(lda_result[iris.target==0, 0], lda_result[iris.target==0, 1], color='r')
>>> plt.scatter(lda_result[iris.target==1, 0], lda_result[iris.target==1, 1], color='g')
>>> plt.scatter(lda_result[iris.target==2, 0], lda_result[iris.target==2, 1], color='b')
>>> plt.title('LDA on iris')
# for NMF
>>> plt.subplot(1,3,3)
>>> plt.scatter(nmf_result[iris.target==0, 0], nmf_result[iris.target==0, 1], color='r')
>>> plt.scatter(nmf_result[iris.target==1, 0], nmf_result[iris.target==1, 1], color='g')
>>> plt.scatter(nmf_result[iris.target==2, 0], nmf_result[iris.target==2, 1], color='b')
>>> plt.title('NMF on iris')
>>> plt.show()
查看效果
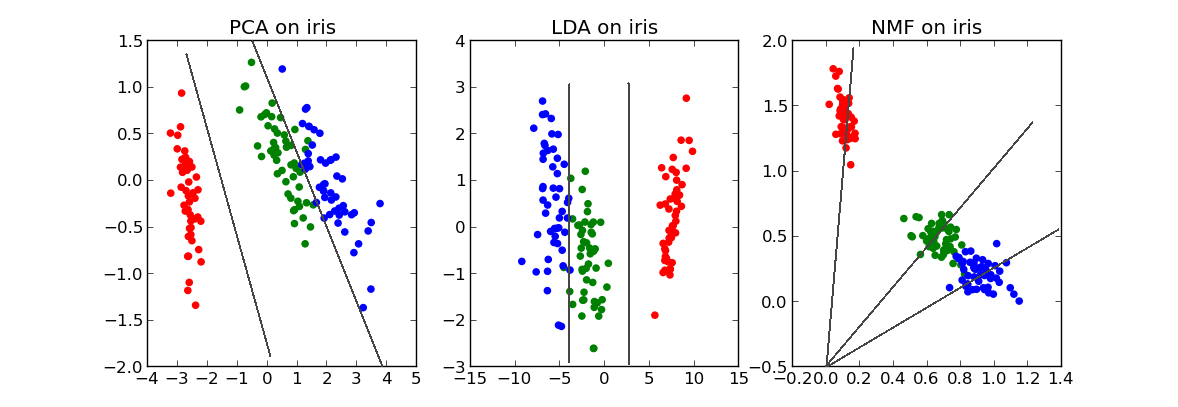
每副图中的灰色直线是我添加上去的,这些直线可以看出新数据的不同特点。