2014-12-22
本文介绍了隐语义模型和NMF(非负矩阵分解)。
隐语义模型
我当前是在推荐系统和文本分类中遇到过“隐语义模型”,也只是刚刚接触。那么,什么是隐语义模型?我们通过两个例子来理解一下。
向用户推荐物品
在推荐系统中,可以通过隐含语义模型将用户(user)和物品(item)自动分类,这些类别是自动生成的。这些类别也可以叫做“隐含的分类”,也许我们看不懂。每个用户或者物品会被分到多个类别中,属于某个类别的权重会被计算出来。
假设现在有一个大小为m×n的评分矩阵V,包含了m个用户对n个物品的评分,评分从0到5,值越大代表越喜欢,0代表没有打分。设定共有r个隐含的分类。通过一些方法,将V展开为两个相乘的矩阵:
V = W*H
其中,W的大小为m×r,H的大小为r×n。在隐语义模型中,W(i,j)被解释为用户i属于类别j的权重,H(a,b)被解释为物品b属于类别a的的权重。
如果用户u对物品i没有评分,可以将这个评分r(u,i)预测为:
r(u,i) = sum(W(i, :) .* H(:, i)) // 向量点乘
据此可以构建一个推荐系统。
文本分类
这个类似上面的推荐系统。我在 词袋模型与文档-词矩阵介绍过文档-词矩阵。我们将数据集中的一堆文本构造成文档-词矩阵V,如果共有m个文本,n个单词,那么V的大小为m×n。V(i,j)表示文档i中出现单词j的次数。
设定共有r个隐含的分类。通过一些方法,将V展开为两个相乘的矩阵:
V = W*H
其中,W的大小为m×r,H的大小为r×n。在隐语义模型中,W(i,j)被解释为文档i属于类别j的权重,H(a,b)被解释为单词b属于类别a的的权重。
对于一个文档,其权重最大的类别被看作是该文档的类别。由于设定共有r个隐含的分类,分类结果也是r个份分类。
NMF
NMF,全称为non-negative matrix factorization,翻译为“非负矩阵分解”,可以用于隐语义模型。非负矩阵,就是矩阵中的每个元素都是非负的。将非负矩阵V分解为两个非负矩阵W和H的乘,叫做非负矩阵分解。那么,该怎么分解呢?在下面的这篇论文里,给出了两个方法并给出了证明。
Lee D D, Seung H S. Algorithms for non-negative matrix factorization[C]//Advances in neural information processing systems. 2001: 556-562.
方法1
定义:
[latex] ||A-B||^2 = \sum_{ij}(A_{ij} - B_{ij})^2 [/latex]
目标是最小化[latex]||V-WH||^2[/latex],初始化W和H后(可以将每个元素利用随机数初始化),按照下面的原则迭代更新W和H,直到W和H几乎不再变化,或者WH非常接近V。
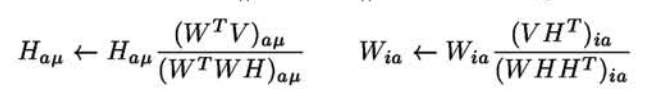
方法2
定义: [latex] D(A||B) = \sum_{ij} (A_{ij} log\frac{A_{ij}}{B_{ij}} - A_{ij} + B_{ij}) [/latex]
当[latex]\sum_{ij}A_{ij} = \sum_{ij}B_{ij} = 1[/latex]时,上面的式子就退化成了KL散度(或者叫相对熵)。
这个方法的目标是最小化[latex]D(V||WH)[/latex]。初始化W和H后(可以将每个元素利用随机数初始化),按照下面的原则迭代更新W和H,直到W和H几乎不再变化,或者WH非常接近V。
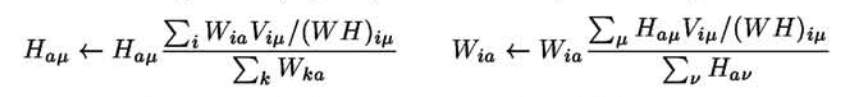
参考
项亮的《推荐系统实践》在第2章第5节提到了隐语义模型,并给出了一个基于梯度下降的矩阵分解方法(不是NMF)。
《集体智慧编程》第10章给出了NMF的浅显解释以及python实现。
下面的这篇论文探索了如何使用NMF进行文本分类:
Xu W, Liu X, Gong Y. Document clustering based on non-negative matrix factorization[C]//Proceedings of the 26th annual international ACM SIGIR conference on Research and development in informaion retrieval. ACM, 2003: 267-273.