2014-8-14
层次聚类,分为自顶向下和自底向上两种。
自顶向下,初始时将数据集中的所有数据对象看做是一个簇,而后根据某些规则逐步细分,直到某一终止条件。
自底向上,先把每一对象看做一个簇,使用迭代的方法处理这些簇,在每次迭代中将根据某一规则计算出的最相近的两个簇合并为一个簇,直到簇的数量达到达到指定的值。
本文只说说自底向上的层次聚类方法。
上面已经给出了自底向上的实现思路,现在细化一下。
如何计算两个簇之间的相似度
下面给出几种方法,这些方法砸很多资料上都有:
对于两个簇A和B,A中有m个数据对象,A(i)是A中的第i个数据对象;B中有n个数据对象,B(j)是B中的第j个数据对象,那么A和B的相近程度可用下面的方法来度量
最小距离: 计算每个A(i)与每个B(j)的距离,共有m*n个距离,这些距离的最小值即为最小距离。
最大距离: 计算每个A(i)与每个B(j)的距离,共有m*n个距离,这些距离的最大值即为最大距离。
平均距离: 计算每个A(i)与每个B(j)的距离,共有m*n个距离,这些距离的均值即为平均距离。
均值距离: 求出簇A的所有数据对象的均值a,和簇B的均值b,a和b的距离称作均值距离。
举个例子
下图是基于均值距离的对一个数据集的层次聚类分析: 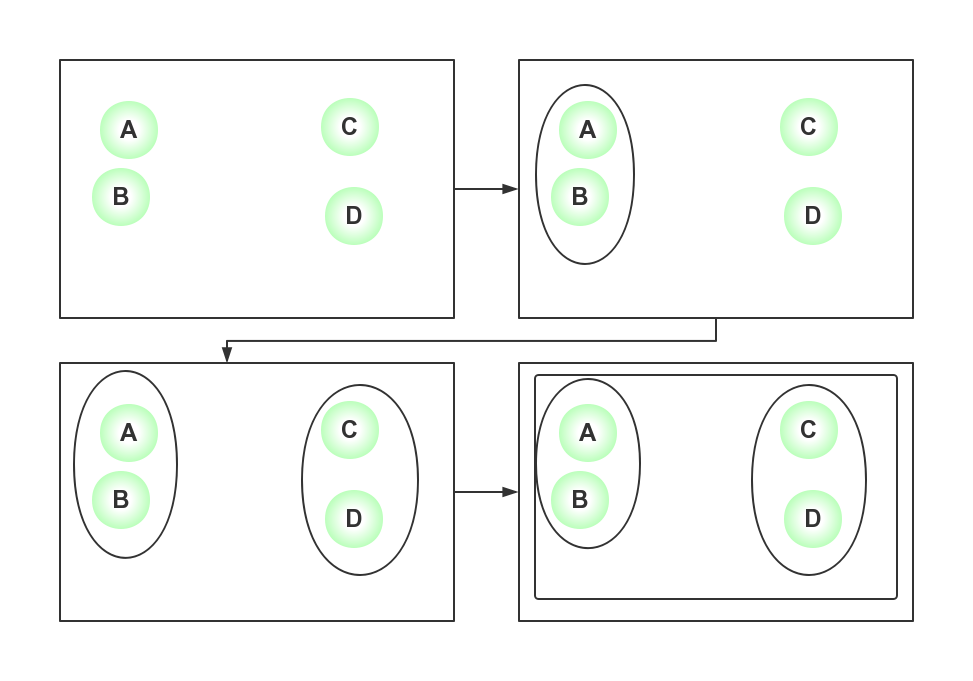
数据集中有四个数据对象A、B、C、D,
- 在开始时,这四个对象各自为一个簇;
- 之后发现簇A和簇B距离最近,于是将其合并为一个簇AB,现在剩下三个簇;
- 簇C和簇D距离最近,合并为簇CD,此时剩下两个簇;
- 簇AB和簇CD距离最近,合并为一个簇ABCD,剩下一个簇,结束。
好了,现在思路很清楚了,为了少造轮子,我们看一下在Matlab中如何层次聚类。
Matlab
数据如下:
dataset = [1, 1;
1, 2;
5, 5;
6, 6 ];
数据集dataset中有4个数据对象,第1个(第1行)数据对象(1,1)认为是簇1,第2行数据对象认为是簇2,依次类推。
使用linkage函数,基于欧几里得距离和均值距离得到聚类树:
Z = linkage(data, 'centroid', 'euclidean');
Z的结果如下:
Z =
1.0000 2.0000 1.0000
3.0000 4.0000 1.4142
5.0000 6.0000 6.0208
Z是一个只有3列的矩阵,每一行代表一次聚类结果。前两列表示是哪两个簇,第三列是这两个簇之间的距离。Z的每一行也认为是生成的一个新的簇。例如Z的第1行(1.0000 2.0000 1.0000)意思是簇1和簇2生成簇5,簇1和簇2之间的均值距离是1;Z的第2行3.0000 4.0000 1.4142意思是簇3和簇4生成簇6,簇3和簇4之间的均值距离是1.4142;Z的第3行5.0000 6.0000 6.0208意思是簇5和簇6生成簇7,簇5和簇6之间的均值距离是6.0208。
然后,我们用把这个聚类树可视化:
dendrogram(Z);

横坐标表示簇的编号,纵坐标表示簇之间的距离。
如果我们想要将这个数据集划分为2个簇,可以:
label = cluster(Z,'maxclust', 2);
label的值是:
label =
1
1
2
2
这些标号和数据集中的每个数据对象一一对应。